This is Cylc’s built in way of dealing with parameterized tasks.
[task parameters]
# You can explicitly list what you are doing
run = 1..20
colour = blue yellow
[scheduling]
[[graph]]
R1 = common_setup => task<colour><run> => common_end
[runtime]
# a couple of different ways of passing the parameter into
# whatever you are running:
[[task<colour><run>]]
script = my_programme --colour $CYLC_TASK_PARAM_colour
[[environment]]
RUN_NUMBER=$CYLC_TASK_PARAM_colour
Jinja2
reference
You can do something similar with Cylc’s Jinja2 templating.
{% for num in range(10) %}
[scheduling]
[[graph]]
R1 = common_setup => task_{{ num }} => common_end
[runtime]
[[task_{{num}}]]
script = my_programme --arg {{num}}
{% endfor %}
IMO the latter is harder to understand and maintain (and looks funky when parsed).
Thanks to both.
I modified my flow.cylc. A few issues a) workdir shows it ran my task only once instead of two b) out of my four tasks, only first two run, not sure, what happened to last two. In fact , I want to run only last task twice, first three only once. My flow.cylc below:
+++++
[scheduler]
allow implicit tasks = True
[scheduling]
cycling mode = integer
initial cycle point = 1
final cycle point = 2
[[graph]]
R1 = """
run_prep_10km => run_mod_10km => run_prep_2p5km => run_mod_2p5km
"""
[runtime]
[[run_prep_10km]]
script = """
jobid=$(sbatch $MY_DEFAULT_PATH/runjob/run_prep_10km.sh | awk '{print $4}')
echo "Submitted job ID: $jobid"
while squeue -j "$jobid" > /dev/null 2>&1; do
sleep 60
done
sacct -j "$jobid" --format=JobID,State
"""
[[[environment]]]
MY_DEFAULT_PATH = /home/bpabla68/projects/def-yorkaqrl/bpabla68/cylc_learning/ex3
...middle two tasks are clipped from here
[[run_mod_2p5km]]
script = """
jobid=$(sbatch $MY_DEFAULT_PATH/runjob/run_mod_2p5km.sh | awk '{print $4}')
echo "Submitted job ID: $jobid"
while squeue -j "$jobid" ; do
sleep 60
done
sacct -j "$jobid" --format=JobID,State
"""
[[[environment]]]
MY_DEFAULT_PATH = /home/bpabla68/projects/def-yorkaqrl/bpabla68/cylc_learning/ex3
Your workflow configuration above shows you’ve used an R1 recurrence - that means “run once”.
For integer cycling, my example above uses P1, not R1, which is short for R/^/P1 - i.e. run repeatedly from the initial cycle point, with an integer interval of 1. Cycling syntax is explained the scheduling section of the User Guide.
I presume you mean “run directory”? Cylc has the concept of “task work directories” but they are specific to each task instance (cycle-point/task-name) so you won’t find evidence of multiple runs in those.
In any case, just look at the scheduler log to see exactly what happened during your run.
That presumably means your second task failed, because the third one triggers off of the success of the second. Check the scheduler log to see that, and then check the job logs of the second task to see why it failed.
A couple of other things, from looking at your flow.cylc:
Your task names suggest you are running atmospheric models, for which we’d typically use datetime cycling, not integer cycling. The cycle point values can be used to set the model start points.
You are running local background jobs that internally submit the models to Slurm and then explicitly poll for the Slurm jobs to finish. You don’t need to do that, just define a platform with Slurm as the job runner and Cylc will handle job submission and job management for you.
now able to run same task multiple times. By looking at the job output in 1/ and 2/ directories of task, it looks like instance #2 ran first, and then ran instance #1. Is that normal? I thought instance #1 should run first, and then second one.
You guessed right, eventually I have to run AQ models with CYLC, as a rookie, I am just playing with small example hellow_world type examples. My read on documentation is yet hard i.e. struggling with syntax. What possible names/keyword goes in [ ], [[ ]]. Are names defined left to = sign are reserved CYLC keywords or any user defined name. Can you please point me to a site, which has couple of practical flow.cylc and global.cylc examples. Any text book you recommend? Any site with CYLC 101 with practical examples.
started working on your last point i.e. moving some of the stuff from flow.cylc to global.cylc.
name of platform ?.
Note, when posting here you can enclose code blocks in triple single back-quotes (and inlined code in single back-quotes) to format it properly. I’ve been editing your posts to add quoting for readability.
I presume you mean cycle points 1 and 2? Cylc famously handles cycling properly, unlike other workflow managers: if there is no dependence between two tasks in different cycles then (because there is no dependence between them!) they should be able to run at the same time, or even out of order.
If you don’t want them to run at the same time, that presumably means the second task depends (directly or indirectly) on the outputs of the first, in which case your dependency graph should reflect those relationships.
The following example runs tasks a and b twice (once in each cycle points, 1 and 2):
[scheduling]
cycling mode = integer
initial cycle point = 1
final cycle point = 2
[[graph]]
P1 = """
a
b[-P1] => b
"""
[runtime]
[[root]]
script = sleep 5
[[a]]
# ...
[[b]]
# ...
… but 1/a and 2/a can both run at the same time, whereas 2/b has to wait until 1/b is finished.
You can run this example (try it, with cylc vip --no-detach) and you’ll see that 1/a, 2/a, 1/b all submit at once, at startup, then 2/b submits later, once 1/b succeeds.
Cylc has to be able to manage a wide variety of complicated cycling workflows, so the syntax has to be rich enough to express all of that. However, it’s really not difficult for everyday use cases (only the cycling syntax has a bit of a learning curve - other config items map pretty directly to core concepts).
. Can you please point me to a site, which has couple of practical flow.cylc and global.cylc. Any text book you recommend? Any site with CYLC 101 with practical examples.
The online documentation has everything you’ve asked for. There is a tutorial section that takes you through the basics, the main User Guide, and a Reference section with exact details of what can go in workflow and global config files.
What possible names/keyword goes in [ ], [[ ]]. Are names defined left to = sign are reserved CYLC keywords or any user defined name.
That depends: many items are reserved keywords, but some things are (necessarily) user-defined - such as task names.
Use cylc validate frequently when writing or modifying your flow.cylc file, to catch errors.
You can’t just move stuff from flow.cylc to global.cylc - the former is a workflow config file, the latter is for settings (such as platform definitions) that affect all Cylc workflows and schedulers. You can override central global config items with a user global config file, but very few global items (if any) are valid as workflow config items - they are different beasts.
Got : [jobs-submit err] No matching platform "cedar" found
Did you put your global config file in one of the valid locations, where Cylc knows to find it?
My read on documentation is yet hard i.e. struggling with syntax.
If I were starting again I’d really appreciate the Cylc VSCode extension - it scrapes the settings right out of the codebase so the popups tell you what each config does:
I want to run 3 instances of run_mod_10km, one after another in same cycle point i.e. when A finishes, first instance of B should start, when it finishes, it should start second instance etc. In terms of timeline, it is the same time for workflow. How can I achieve it, Following is firing 3instances of B from A at the same time, which I don’t want. Thanks for any help.
A => B<m=1>
B<m-1> => B<m> # (works for any M, for m=1..M)
Thanks Hilary.
Your second suggestion worked. First one, R1 = "A => B1 => B2 => B3" worked partially. Though graph looks OK, only A ran, none of B instance started, no error in log file.
So I will implement your second approach. In my case, I have to run three instances of B in the same directory instead of three i.e. B1 produces restart file, which B2 reads, similarly B2 produces restart file, which B3 reads.
Is there way to force B’s to run in the same work directory?
Currently it does :
What you describe there (including “no error in log file”) is not possible!
That graph is fine, it’s very simple and Cylc will do exactly what it says.
Bear in mind that foo => bar is short for foo:succeeded => bar i.e., it means “run bar if foo succeeds”, and by implication do not run bar if foo fails.
If A ran but B did not, that implies either:
A did not succeed, i.e. it failed
the scheduler log will report that A failed
the job logs for A will show that it failed (job.out, job.err)
or A succeeded and Cylc submitted B, but B’s job submission failed
the scheduler log will report that B’s job submission failed
the job activity log for B will report that job submission failed (job-activity.log)
(Neither of these reflect any problem with Cylc - it’s exactly what’s supposed to happen).
The two approaches are identical, except that task parameters are used to generate the graph in the second case. After parameter expansion, for the same number of tasks, Cylc will see exactly the same graph - so, either your tasks failed as just described, or you made a mistake in your flow.cylc - did you use cylc validate before trying to run it?
The way we usually do this is to tell all 3 tasks to use the same shared workspace for the files they need to exchange. That’s the purpose of the workflow share directory provided by Cylc. The share directory is a sub-directory of the workflow run directory. Task jobs can get this location from their runtime environment.
How you tell each task to use the shared location is down to how the underlying applications are configured. Here’s an example for two tasks, one of which takes its output location from the command line, the other from the environment:
[scheduling]
[[graph]]
R1 = "foo => bar"
[runtime]
[[foo]] # write my output to "data" in the workflow share dir
script = run_foo.sh --output=$CYLC_WORKFLOW_SHARE_DIR/data
[[bar]] # read my input from "data" in the workflow share dir
script = run_bar.py
[[[environment]]]
INPUT_FILE = $CYLC_WORKFLOW_SHARE_DIR/data
(Note in a cycling workflow you probably want to use cycle-specific sub-directories of the share directory).
That said, if your applications’ IO locations cannot be configured and they can only read and write from their current working directory (unlikely, but possible!) you CAN make Cylc use a common work directory for them.
If several tasks need to exchange files and simply read and write from their from current working directory, setting work sub-directory can be used to override the default to make them all use the same workspace.
Thanks Hilary for your help. It worked i.e. can make use of share directory to achieve my goal. Just curious, INPUT_FILE in above example is any user defined name i.e. not CYLC reserved keyword.Are cylic reserved keywords start with CYLC string in front?
INPUT_FILE
That’s right - I just meant $INTPUT_FILE as an environment variable that my (example/fake) application run_bar.py expects the user to define as the path to its inputs. (i.e. the application get its input file location from the environment, as opposed to from the command line, or from a config file, or whatever).
Any non user-defined environment variable provided to task jobs by Cylc will start with CYLC_. These are not reserved keywords as such, because they shouldn’t be defined in a flow.cylc file under any circumstances. They are provided to jobs at runtime by the scheduler.
Examples are:
$CYLC_WORKFLOW_SHARE_DIR (explained above)
$CYLC_TASK_CYCLE_POINT - so the job knows the cycle of the task that it represents
[[graph]]
R1 = """
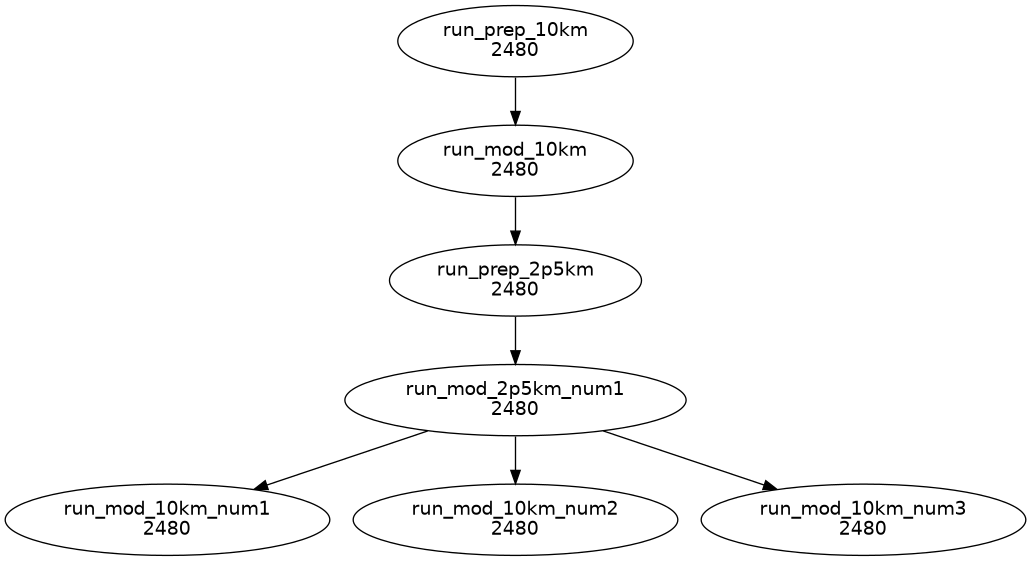
run_prep_10km => run_mod_10km => run_prep_2p5km => run_mod_2p5km<num=1> ...line #1
run_mod_2p5km<num-1> => run_mod_10km<num> ...line #2
"""
My wish list list is to run things in this order
A => B =>C =>D1 =>D2 =>D3
cylc graph [-c -t] looks OK, but not sure it is correct flow as it is splitted into two parts.
Order of jobs submitted does not seem correct to me....
(ENV) [bpabla68@cedar1 cylc-run]$ squeue --me
JOBID USER ACCOUNT NAME ST TIME_LEFT NODES CPUS TRES_PER_N MIN_MEM NODELIST (REASON)
62323129 bpabla68 def-yorkaqrl run_prep_10km R 29:56 1 32 N/A 3G cdr1661 (Prolog)
62323128 bpabla68 def-yorkaqrl run_mod_2p5km PD 5:00:00 16 729 N/A 3G (Priority)
Probably just something like what @wxtim suggests.
(It’s not clear to me exactly what you want since A => B => C => D1 => D2 => D3 doesn’t seem to to map directly to the 2p5km and 10km tasks you have.)
If two tasks, or groups of tasks, are disconnected (e.g. like your split into two parts, which you seem not to want) then it just means you have not put a dependency (=>) between them.
Using task parameters make it a bit less obvious at a glance, but you can expand the parameters yourself to get the explicit version:
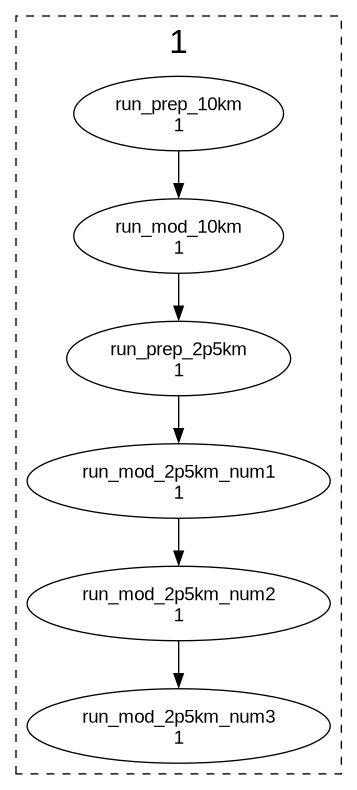
Thanks Tim and Hilary. Indeed it was typo on second line. My apology. I want to run one instance of run_prep_10km, run_mod_10km, run_prep_2p5km, and three instances of run_mod_2p5km due to restart file. Following seems correct order..